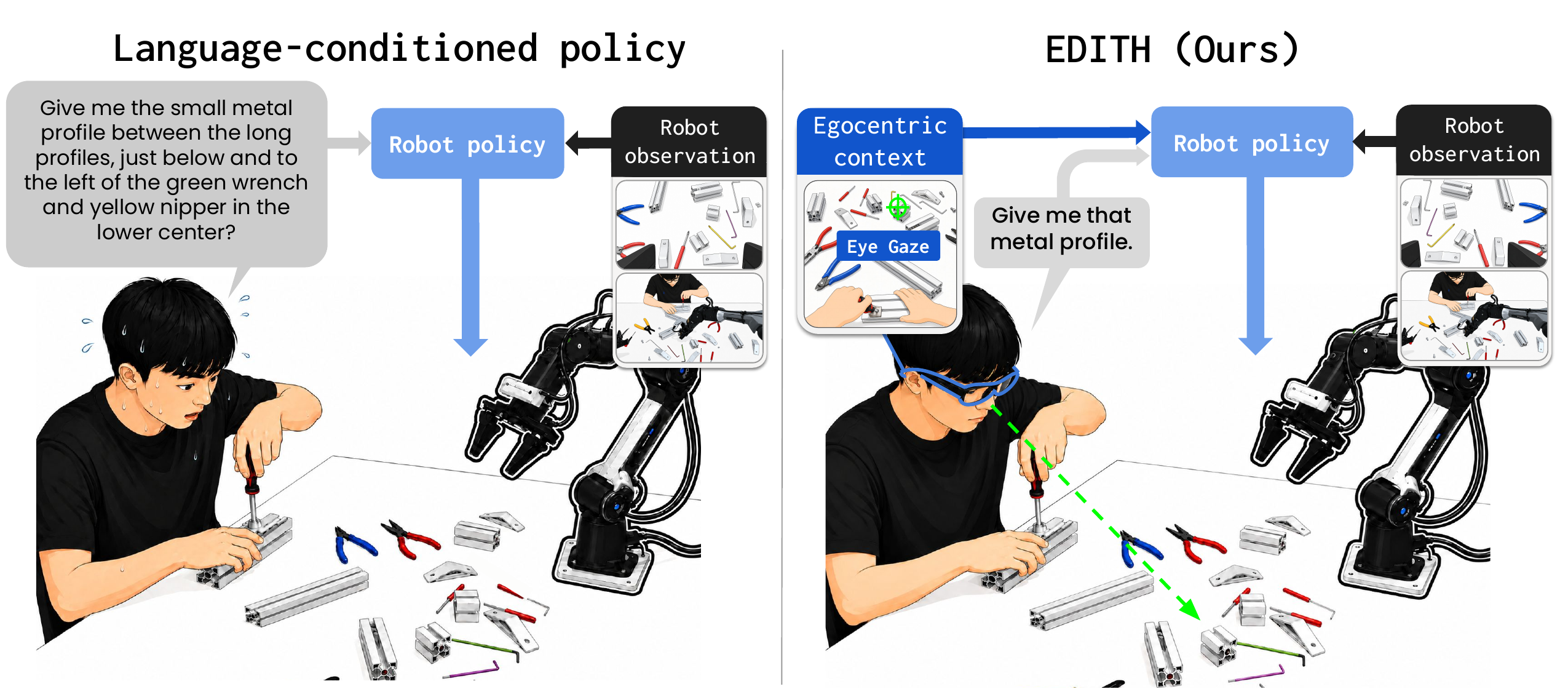
Language-conditioned policies require humans to fully verbalize
their intent through language, which is often cumbersome and
imprecise.
To enable robots to understand human nonverbal signals as well,
we use the human's egocentric view and gaze as inputs to the
robot control policy.
Method
Hardware System
We build a hardware system that streams the human's first-person view,
gaze, and speech in real time, and synchronizes them with the robot's
observations.
Capturing human signals via smartglasses.
Bimanual Robot
Why first-person view and gaze?
First-person view and gaze represent human nonverbal signals by
capturing what the human is doing and where their attention is
focused. Together, these streams provide cues for a robot policy to
infer the human's underlying intent and needs.
Capturing human signals via smartglasses.
Using
Project Aria glasses,
EDITH streams first-person RGB, gaze, and speech to the robot server,
transcribes speech into \(\ell_t\), and synchronizes the
signals with robot observations \(o_t\) to produce
\((C_t^{\mathrm{ego}}, \ell_t, o_t)\)
at each timestep.
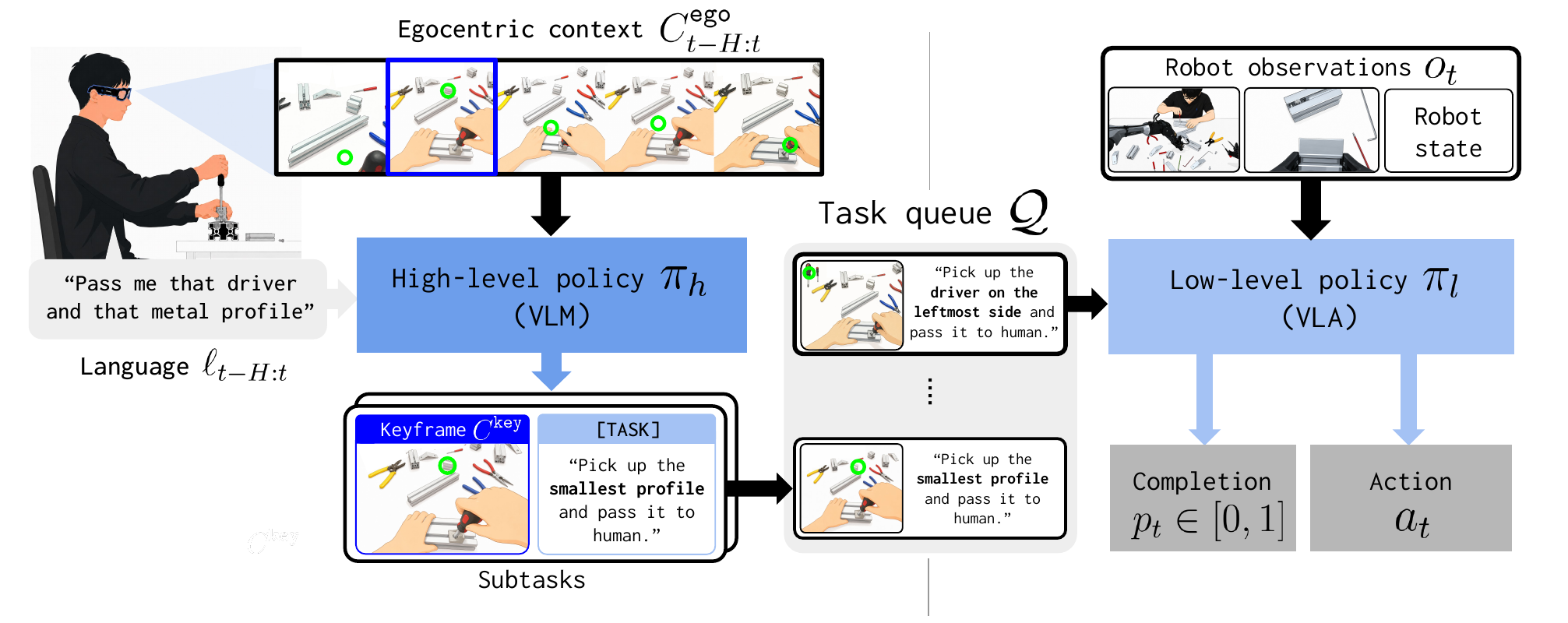
Policy Design
Human signals contain rich information but are often noisy and
transient. To effectively process such signals, we propose a
hierarchical policy that decouples inferring the human's intent
from producing low-level actions. It consists of a
and a
.
Overall Design
EDITH converts verbal instructions and egocentric context into
instruction-keyframe subtasks, stores them in \(Q\), and executes
each subtask with the robot policy.
Results
EDITH improves task success while reducing the user's instruction burden.
Results are reported with success rate (SR) and task progress (TP)
over 48 trials per task per method, plus a user study on instruction workload.
Baselines
\(\pi_l^{\mathrm{lang}}\)
\(\pi_{0.5}\) finetuned with task-specific demonstration data.
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
Hierarchical policy employing a VLM as the high-level planner, similar to Hi Robot.
\(\pi_l^{\mathrm{ego+lang}}\)
\(\pi_{0.5}\) finetuned with task-specific demonstration data, additionally conditioned on egocentric context.
Main Results
EDITH achieves 59.7% average success rate and 84.7% task
progress by translating nonverbal human signals into
keyframe-grounded subtasks.
Language-only baselines, \(\pi_l^{\mathrm{lang}}\) and
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\), do not use
egocentric context and
perform poorly
,
highlighting the importance of egocentric context for grounding
nonverbal intent.
Directly conditioning an end-to-end policy on the current
egocentric context yields inconsistent benefits: it helps only
when gaze remains on the target, but degrades when attention is
intermittent. EDITH handles both cases more consistently by
monitoring intent separately through the high-level policy.
User Study on 16 Participants
EDITH reduces workload of humans in conveying their intent to the robot
We conducted the user study with 16 participants to evaluate
the workload of conveying intent to the robot. The study was
IRB-approved.
EDITH reduces the effort users must spend to convey their intent.
Compared with the \(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
baseline, EDITH substantially lowers instruction workload on both
Muffin-Serving and Tool-Passing, and the reduction is statistically
significant (\(p < 0.001\)).
The baseline places much of the burden on the user: participants
must verbally describe each target object precisely enough to
disambiguate it, including attributes such as color, position, and
surrounding objects. EDITH instead lets users pair brief utterances
with nonverbal expressions such as gaze and pointing, removing the
need to fully verbalize the target.
Analysis
Q: How does EDITH perform when humans are distracted?
A:
In natural interaction, human attention can shift to unrelated
activities such as briefly checking a phone. We test this in
Muffin-Serving by having the human alternate between checking a text
message and requesting muffins until all three are requested. EDITH's
SR and TP remain comparable to the non-distracted setting, with only a
0.5% relative drop in task progress.
Q: What is the effect of using keyframe as a subtask representation?
A:
To isolate the keyframe's contribution, we compare EDITH with a
hierarchical no-keyframe baseline: \(\pi_h\) still maps egocentric
context and language into subtasks, but \(\pi_l\) receives only the
subtask instruction. Removing the keyframe drops SR/TP by 49.9/51.5
points on average. This happens because \(\pi_h\) can hallucinate the
wrong target when verbalizing nonverbal signals, and semantically
correct subtasks can be phrased in ways unseen during \(\pi_l\)'s
training. Since EDITH retrieves the keyframe from the egocentric stream
instead of generating it as text, it avoids both hallucination and
ambiguous phrasing.
100806040200
Muffin-Serving
2.150.0
SR (%)
11.880.6
TP (%)
Tumbler-Sorting
2.545.8
SR (%)
36.883.0
TP (%)
Tool-Passing
25.083.3
SR (%)
51.090.6
TP (%)
EDITH w/o \(C^{\mathrm{key}}\)EDITH
Comparison to \(\pi_l^{\mathrm{lang}}\) provided with a
fully-specified language instruction.
We also evaluate \(\pi_l^{\mathrm{lang}}\) with fully specified
instructions that explicitly name each target object, and compare
it with EDITH using underspecified language accompanied by
nonverbal signals.
Even without fully specified language, EDITH achieves higher
success rate, showing that it effectively leverages nonverbal
signals to capture human intent. In contrast,
\(\pi_l^{\mathrm{lang}}\) often fails even with detailed verbal
instructions because the evaluation scenes contain densely
cluttered and visually similar targets.
In Tool-Passing, for example, multiple screwdrivers look similar;
in Muffin-Serving, muffins differ only by small toppings. Requiring
users to fully verbalize these details also imposes substantial
workload. EDITH matches or surpasses fully specified language
without requiring that burden.
100806040200
Muffin-Serving
16.750.0
SR (%)
41.080.6
TP (%)
Tumbler-Sorting
43.845.8
SR (%)
76.483.0
TP (%)
Tool-Passing
56.383.3
SR (%)
74.590.6
TP (%)
\(\pi_l^{\mathrm{lang}}\) fully specifiedEDITH
Participants
We recruited 16 participants (6 female, 10 male; ages 20-40).
All participants were native Korean speakers with no or limited
prior experience interacting with collaborative robots. Each
participant was compensated 10,000 KRW for approximately 30
minutes of participation.
Procedure
Each participant experienced both methods across the two tasks
in a within-subjects design.
Orientation. Participants first attended a brief
orientation session that introduced the study purpose and procedure,
then watched videos of the robot performing the tasks to become
familiar with the setup. To reduce potential bias, the two methods
were referred to only as color labels: System Blue for the baseline
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\), and System
Purple for EDITH.
Condition-specific instructions. In the baseline
condition, participants used verbal instructions alone, including
attributes such as color, location, and name, without gestures or
gaze. In the EDITH condition, they used brief verbal references
together with nonverbal signals such as pointing gestures and gaze.
Tasks and goal presentation. At the beginning of
each trial, participants were shown a goal image. Muffin-Serving
goals showed a specified muffin served on a plate, while Passing
Tools goals showed an assembly instruction diagram. Goals were
shown as images, not text, so participants would express intent in
their own words rather than copy written instructions.
Trials and survey. For each task-condition
combination, participants performed three trials with different
goals. Task and condition order were counterbalanced. After each
condition, participants completed the survey, resulting in 12 trials
and 4 survey responses per participant.
Survey Items
Instruction workload. We adapted four items
corresponding to NASA-TLX dimensions relevant to our context and
converted them to a 7-point Likert scale (1 = strongly disagree,
7 = strongly agree). The survey was administered in Korean; we
report English translations of the items below.
Expressing my intention to the robot required a lot of mental effort.
It was difficult to successfully convey what I wanted to the robot.
I had to put in a lot of effort to get the robot to perform the behavior I wanted.
I felt frustrated, annoyed, or irritated while expressing my intention to the robot.
Statistical Analysis
Because Likert responses may not satisfy the normality assumption,
we used the Wilcoxon signed-rank test for paired comparisons
between the two conditions. Effect sizes are reported as
\(r = Z / \sqrt{N}\).
Survey Results
EDITH produced lower workload scores than the baseline on all four
survey items and both tasks, with every comparison statistically
significant (p < 0.01). Effect sizes ranged from \(r = 0.74\) to
\(0.89\), indicating large effects.
The largest effects appeared for mental demand and successful intent
conveyance, suggesting that precisely verbalizing target attributes
is a major source of workload in the language-only baseline. Under
EDITH, workload stayed consistently low across tasks, indicating
that nonverbal cues reduced the burden of conveying intent.
*** p < 0.001, ** p < 0.01.
Serving Muffins
Mean(SD)
Q1. Expressing my intention to the robot required a lot of mental effort.
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
121453
5.19(1.52)***EDITH
6343
2.44(1.50)
Q2. It was difficult to successfully convey what I wanted to the robot.
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
11833
5.19(1.52)**EDITH
6514
2.44(1.63)
Q3. I had to put in a lot of effort to get the robot to perform the behavior I wanted.
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
131443
5.00(1.59)**EDITH
64321
2.50(1.79)
Q4. I felt frustrated, annoyed, or irritated while expressing my intention to the robot.
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
2241241
3.94(1.95)**EDITH
74122
2.25(1.48)
0481216
Number of Responses
Passing Tools
Mean(SD)
Q1. Expressing my intention to the robot required a lot of mental effort.
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
111274
4.56(1.46)**EDITH
5641
2.19(1.28)
Q2. It was difficult to successfully convey what I wanted to the robot.
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
214531
4.56(1.41)**EDITH
57211
2.25(1.44)
Q3. I had to put in a lot of effort to get the robot to perform the behavior I wanted.
\(\pi_h^{\mathrm{lang}} + \pi_l^{\mathrm{lang}}\)
14344
4.38(1.31)**EDITH
651211
2.38(1.59)
Q4. I felt frustrated, annoyed, or irritated while expressing my intention to the robot.
Three tasks require grounding underspecified language in nonverbal signals.
In each task, the language instruction does not fully specify the
target: the robot must interpret the human's eye gaze or gestures
to identify the target objects and complete the requested task.
Task 01
Muffin-Serving
Six muffins are densely arranged. The human requests three
muffins while consecutively pointing at each one.
Task 02
Tumbler-Sorting
Five tumblers and two baskets are placed on the table. The human
points to tumblers and baskets to specify a multi-step sorting request.
Task 03
Tool-Passing
While the human is assembling something with both hands, they
request the tool they need through a brief utterance and a
glance, and the robot hands it over.
If you find our work useful, please cite the paper using the
BibTeX entry on the right.
@article{lee2026hierarchicalpoliciesverbalegocentric,
title={Hierarchical Policies from Verbal and Egocentric Human Signals for Natural Human-Robot Interaction},
author={Dongjun Lee and Juheon Choi and Dong Kyu Shin and Sinjae Kang and Kimin Lee},
year={2026},
url={https://arxiv.org/abs/2606.10276},
}